Een computer die een video van een slinger bekijkt en daaruit de natuurwetten afleidt die de slingerbeweging beschrijven, het is geen toekomstmuziek meer. De AI-wetenschapper bestaat al en helpt ons om de geheimen van het universum te ontcijferen.
 Koen Vervloesem
Koen Vervloesem
De wetenschap wil orde brengen in de op het eerste gezicht wanordelijke gebeurtenissen in het universum. Door de gebeurtenissen die we waarnemen in een model te gieten, kunnen we voorspellen wat de (nabije) toekomst ons brengt. Zo kunnen we met formules de baan van een kogel berekenen, de beweging van een slinger beschrijven en nog vele andere zaken.
De wiskunde speelt een belangrijke rol in de wetenschap, en opvallend is dat veel natuurwetten eigenlijk vrij eenvoudige wiskundige formules zijn. Het heeft Nobelprijswinnaar Eugene Wigner ertoe gebracht om te spreken over The Unreasonable Effectiveness of Mathematics in the Natural Sciences, de titel van een artikel dat de Hongaars-Amerikaanse natuurkundige in 1960 schreef.
Hard werk
Hoe eenvoudig sommige natuurwetten ook zijn, hun ontdekking is dat niet. Het vereist vaak turen naar grote datasets, allerlei aanpakken uitproberen én een grote dosis geluk of een plots moment van inzicht. Het beroep van wetenschapper is hard werken, waarvan buitenstaanders vaak alleen de successen te zien krijgen. Zo had Johannes Kepler er vier jaar voor nodig om uit de observaties van sterrenkundige Tycho Brahe te bepalen dat Mars een ellipsvormige baan volgt.
Kan een deel van dat werk niet overgenomen worden door computers? De successen van neurale netwerken de laatste jaren om patronen te herkennen in grote hoeveelheden data lijken dat te suggereren. Maar uit alle mogelijke wiskundige formules op een eenvoudige formule komen die de beweging van een slinger beschrijft, is wel een andere taak dan een kat of hond herkennen in een foto.
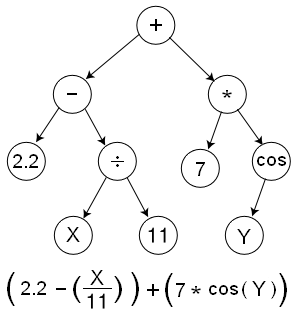 |
|
Elke wiskundige formule kan in de vorm van |
Boomstructuren
Al sinds de jaren ’70 bestaat er een aanpak die redelijk goed werkt. Die algoritmes worden wel eens machine scientists genoemd en de algemene aanpak heet symbolische regressie. Men stelt wiskundige formules dan voor als boomstructuren waarin – naast wiskundige bewerkingen zoals +, -, * en / – ook variabelen voorkomen die naar de waargenomen data verwijzen. Men probeert dan een boomstructuur te vinden die de observaties zo goed mogelijk beschrijft, en dat is dan het model van de werkelijkheid.
Het voordeel van deze aanpak, vergeleken met andere modellen, is dat je veel vrijheid hebt in de wiskundige structuur: alle mogelijke formules komen in aanmerking. Dus je hoeft op voorhand geen al te grote veronderstellingen te maken over de vorm van de formule die je zoekt.
Bij andere aanpakken ligt de structuur daarentegen vaak vast. Zo heeft een neuraal netwerk een specifieke structuur, en het enige wat je kunt aanpassen, zijn wat hyperparameters zoals het aantal lagen in het netwerk en het aantal neuronen per laag. De zoektocht naar een model dat de observaties beschrijft, blijft dan ook beperkt tot het universum van modellen dat zich aan deze structuur houdt. In feite ligt het model vast in de vorm van een generiek model waarvan je naar de beste parameters zoekt. Heeft het beste model een andere structuur? Dan ga je het nooit vinden. Bij symbolische regressie daarentegen varieer je zowel het model als de parameters.
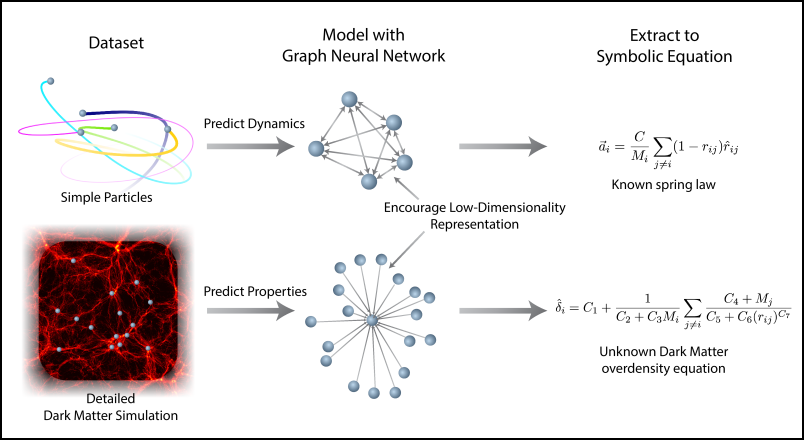 |
| Genetische algoritmes passen delen van de boomstructuren aan en bekijken welke formules de observaties het best beschrijven (bron: Marta Sales-Pardo, Roger Guimerà) |
Genetische algoritmes
Bij symbolische regressie begint men dan met een willekeurige formule en kijkt in hoeverre die de observaties correct beschrijft. In het begin zal dat helemaal niet correct zijn. Maar dan past het algoritme een willekeurige bewerking of variabele in de formule aan: een knooppunt in de boomstructuur. Een + wordt dan bijvoorbeeld een -, of een x een z. Als die formule de observaties beter beschrijft, is men dichter bij de waarheid.
Op dezelfde manier kunnen er ook andere wijzigingen gebeuren aan de formule. Zo kan een hele deelboom verwijderd of toegevoegd worden. Of twee formules kunnen met elkaar gecombineerd worden door een deelboom van de ene te wisselen met een deelboom van de andere.
Door zo te beginnen met een boel willekeurige formules en daaraan willekeurige wijzigingen door te brengen, en dan telkens de beste bij te houden, verkrijg je een verzameling formules die steeds beter je observaties beschrijft. Deze aanpak heet genetische algoritmes: je laat een boel algoritmes zich voortplanten en muteren en je laat de ‘fitste’ (degene die de observaties het best beschrijven) overleven.
En zo kom je uiteindelijk – hopelijk – tot een formule die je observaties (op afrondingen of ruis na) volledig beschrijft. De machinewetenschapper heeft dan autonoom een natuurwet ontdekt. Het programma BACON.3 van Pat Langley ontdekte op deze manier in 1979 de derde wet van Kepler, de wet van Coulomb, de wet van Ohm en Galileo’s wetten voor de slinger en constante versnelling.
De meest voorkomende vergelijkingen
Toch had deze aanpak met genetische algoritmes zijn beperkingen. Vaak leverde ze nodeloos complexe vergelijkingen op. En dat terwijl veel natuurkundige vergelijkingen verrassend eenvoudig zijn. Marta Sales-Pardo en Roger Guimerà kwamen daarom op het idee om niet zomaar met willekeurige vergelijkingen te beginnen, maar met vergelijkingen die lijken op bestaande vergelijkingen.
Ze downloadden dus meer dan vierduizend vergelijkingen van Wikipedia en analyseerden welke vormen daarin het meest voorkwamen. Ze lieten hun algoritme dan ook de vormen die vaker voorkomen vaker uitproberen dan minder voorkomende vormen. Zo zal een eenvoudige a + b vaker voorkomen dan a cosh(b).
Informatie comprimeren
Sales-Pardo en Guimerà pasten in hun algoritme nog een ander inzicht toe: het correcte model is dat model dat de data het beste comprimeert. Als je een wolk van willekeurig verspreide punten wilt beschrijven, kun je niet beter doen dan gewoon de positie van al die punten opsommen. Maar als diezelfde hoeveelheid punten op een rechte lijn liggen die door het nulpunt gaat, kun je die allemaal beschrijven door de helling en hoogte van de lijn.
Bij elke stap waarbij de formules worden aangepast, probeert het algoritme dan ook uit hoe goed de nieuwe formules de data comprimeren. De formules die de data het meest comprimeren, gaan door naar de volgende stap. Daar worden dan weer varianten van gemaakt, die weer worden geselecteerd op hun vermogen om de data te comprimeren. Uiteindelijk kom je zo terecht bij een formule die de data het meest comprimeert, en dat is het correcte model dat de observaties beschrijft.
Nieuwe formules vinden
Sales-Pardo en Guimerà noemden hun algoritme de Bayesian machine scientist (https://www.science.org/doi/10.1126/sciadv.aav6971). Ze hebben die zelf met succes toegepast om een nieuwe oorzaak van celdeling te ontdekken: celdeling hangt niet alleen af van de grootte van de cel, maar ook van hoe hard de cel door zijn buren samengedrukt wordt. Die factor had hun team zelf nooit alleen ontdekt, maar hun machine scientist kwam al na enkele minuten met de eenvoudige formule af.
Daarna hebben ze hun aanpak ook gebruikt om het energieverbruik en vervuilingsniveau van landen te voorspellen (https://www.sciencedirect.com/science/article/pii/S2352550921003729?via%3Dihub) op basis van enkele socio-economische parameters. De formules die hun machine scientist vond, bleken betere voorspellingen op te leveren dan het bestaande veel gebruikte model STIRPAT.
De onderzoekers hebben de code van de Bayesian machine scientist (https://bitbucket.org/rguimera/machine-scientist) gepubliceerd. Andere onderzoekers zijn er al mee aan de slag gegaan, en ook jij kunt dat. Het is een Python-programma dat een soortgelijke interface gebruikt als die van Scikit-Learn (https://scikit-learn.org), een populair pakket voor machine learning in Python.
 |
|
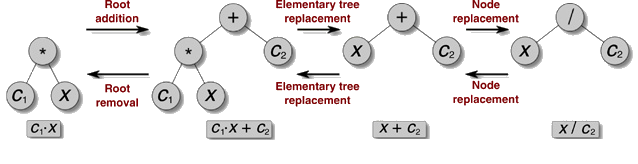
Een neuraal netwerk getraind op observaties wordt omgezet in formules (bron: Miles Cranmer) |
Het beste van twee werelden
Terwijl de Bayesian machine scientist van Sales-Pardo en Guimerà zich afzet tegenover neurale netwerken, combineren andere wetenschappers de sterktes van neurale netwerken met symbolische regressie. Neurale netwerken zijn immers heel goed in het verwerken van grote hoeveelheden data, terwijl symbolische regressie daar al snel tegen zijn limieten botst.
Maar het model dat uit het trainen van een neuraal netwerk komt, is door zijn groot aantal parameters moeilijk te interpreteren door ons. Symbolische regressie daarentegen levert een wiskundige formule op die ons inzicht geeft. De truc is nu om de voordelen van beide systemen te combineren: goede prestaties bij grote hoeveelheden data en toch een inzichtelijke uitkomst.
De gravitatiewet van Newton
Een van die systemen is PySR (https://github.com/MilesCranmer/PySR) van Miles Cranmer. Hij onderzoekt hoe kunstmatige intelligentie astrofysica kan helpen en heeft daarvoor PySR ontwikkeld. Deze software werkt op een hybride manier, deels met een neuraal netwerk, deels symbolisch. Eerst wordt een neuraal netwerk getraind om observaties te voorspellen. Het neuraal netwerk zal specifieke patronen in de observaties gedetecteerd hebben, maar het resultaat is moeilijk te interpreteren.
Het neuraal netwerk wordt zo opgesteld dat het in kleine interne functies wordt onderverdeeld. Nadat het op de observaties is getraind, wordt op de invoer en uitvoer van elke interne functie symbolische regressie toegepast. Het resultaat is een formule die de interne functie beschrijft. Door die dan samen te nemen, ontdekt PySR de wiskundige formule die de observaties beschrijft. Cranmer slaagde er zo in om met PySR de gravitatiewet van Newton te herontdekken op basis van dertig jaar observaties van NASA’s ruimtesonde Horizons. Diverse andere onderzoeksgroepen zijn ook met PySR aan de slag gegaan (https://astroautomata.com/PySR/#/papers) in allerlei domeinen.